Mistral AI has launched Voxtral Transcribe 2, a pair of powerful new speech-to-text models boasting real-time transcription, low latency, and support for 13 languages, all under open source licensing.
Quick Summary – TLDR:
- Mistral launched two new models: Voxtral Mini Transcribe V2 for batch jobs and Voxtral Realtime for live transcription.
- Ultra-low latency down to 200ms and pricing at just $0.003/minute make it one of the cheapest high-accuracy options available.
- Open weights under Apache 2.0, meaning enterprises can run the model locally on edge devices.
- Supports 13 languages, speaker diarization, word-level timestamps, and domain-specific context biasing.
What Happened?
On February 4, 2026, Paris-based Mistral AI unveiled Voxtral Transcribe 2, a major upgrade to its original speech-to-text platform first launched in July 2025. This new release includes two models optimized for different use cases: Voxtral Mini Transcribe V2 for batch transcription and Voxtral Realtime for live, low-latency speech processing.
The models deliver state-of-the-art transcription accuracy, rivaling top offerings from big names like ElevenLabs, Deepgram, and Google, but at a fraction of the price.
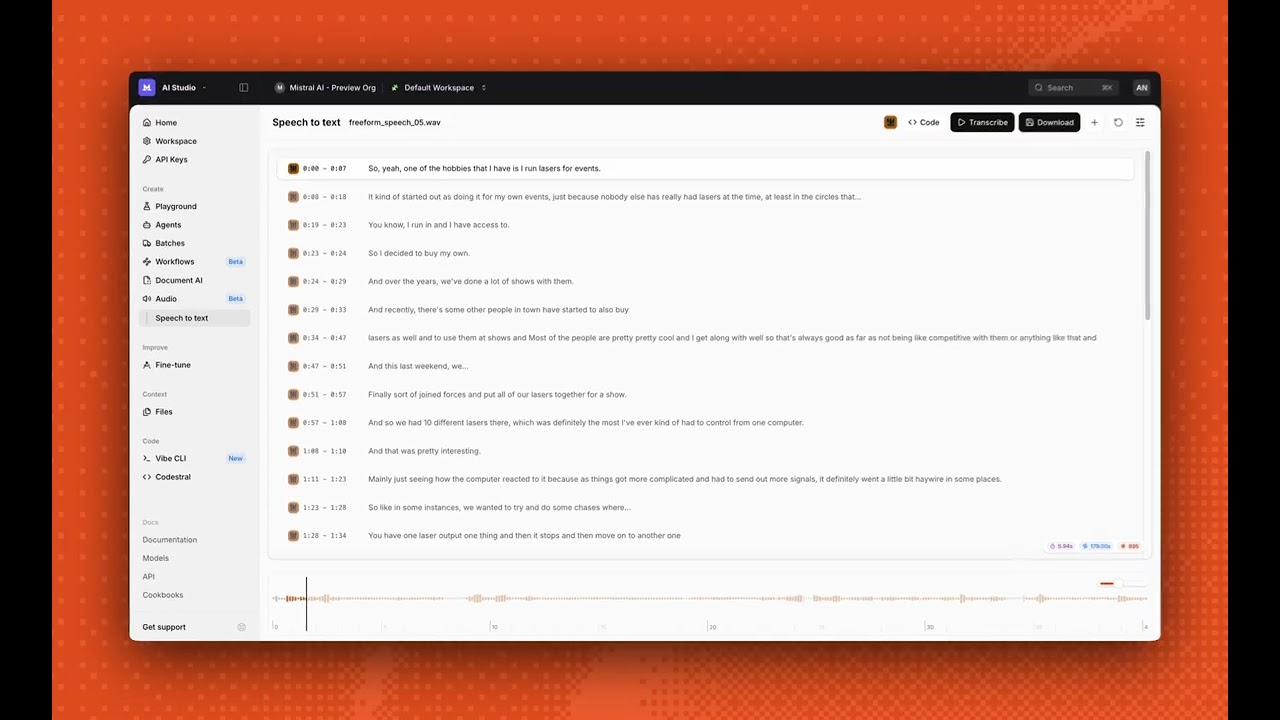
Two Models, One Goal: Speed and Accuracy
Voxtral Mini Transcribe V2 is built for longer audio files and batch processing. It includes:
- Speaker diarization with precise speaker labeling.
- Word-level timestamps.
- Context biasing for up to 100 domain-specific terms.
- Expanded language support for 13 languages including Chinese, Arabic, Hindi, Japanese, and Korean.
Meanwhile, Voxtral Realtime is engineered for live use cases like voice agents and subtitling. It uses a novel streaming architecture that allows it to transcribe incoming audio as it arrives, without batching it first. This enables:
- Latency configurable down to sub-200ms.
- Near-offline accuracy even at 480ms latency.
- Compatibility with real-time apps like virtual assistants, call center automation, and live broadcasts.
Why This Is a Big Deal?
- Cost Advantage: Mistral priced batch transcription at $0.003/minute, nearly 80 percent cheaper than ElevenLabs’ Scribe v2, while still matching or exceeding its accuracy. Even Realtime mode is just $0.006/minute.
- Accuracy: Benchmarks show a 4% word error rate on the FLEURS dataset, outperforming models like GPT-4o Mini Transcribe and Assembly Universal.
- Open Deployment: Voxtral Realtime is released under the Apache 2.0 license, enabling enterprises to deploy on-premise, a major win for industries like healthcare and finance where privacy and compliance (HIPAA, GDPR) are critical.
- Edge Ready: With just 4 billion parameters, the model is small enough to run on laptops and phones, something few competitors can offer.

Built for Enterprise and Global Use
Voxtral 2 supports a wide range of industries:
- Meeting intelligence: Multi-speaker transcription with timestamps at scale.
- Voice assistants: Fast enough for real-time interaction.
- Call centers: Live transcription enables sentiment analysis, CRM integration, and live coaching.
- Media and broadcasting: Generate real-time multilingual subtitles.
- Compliance and audit: Word-level timestamps and diarization simplify regulatory tracking.
Developers can immediately test both models in Mistral Studio’s new audio playground, or download the Realtime model weights from Hugging Face for full local deployment.
SQ Magazine Takeaway
I love what Mistral is doing here. For too long, real-time transcription has either been too expensive, too slow, or too locked into cloud APIs. Mistral is flipping that on its head. With open weights, edge deployment, and insane pricing, they’re not just competing with ElevenLabs or Google, they’re changing the game. If you’re building anything with voice and haven’t tried this yet, you’re already behind. The fact that it supports 13 languages and runs on a laptop? That’s wild. This is the kind of tool that pushes the entire industry forward.